https://doi.org/10.1140/epjb/s10051-024-00717-0
Regular Article - Statistical and Nonlinear Physics
Modeling texts with networks: comparing five approaches to sentence representation
1
Department of Human Sciences, Campus IV, University of Bahia State (UNEB), 44.700-000, Jacobina, Bahia, Brazil
2
Department of Education, Campus I, University of Bahia State (UNEB), 41.150-000, Salvador, Bahia, Brazil
3
Computational Modeling Program, SENAI CIMATEC University Center, 41.650-010, Salvador, Bahia, Brazil
4
Programa de Pós-Graduação em Difusão do Conhecimento (PPGDC), Federal University of Bahia (UFBA), University of Bahia State (UNEB), Bahia Federal Institute of Education, Science and Technology (IFBA), State University of Feira de Santana (UEFS), National Scientific Computing Laboratory (LNCC), SENAI CIMATEC University Center, 40.110-100, Salvador, Bahia, Brazil
Received:
29
March
2024
Accepted:
31
May
2024
Published online:
20
June
2024
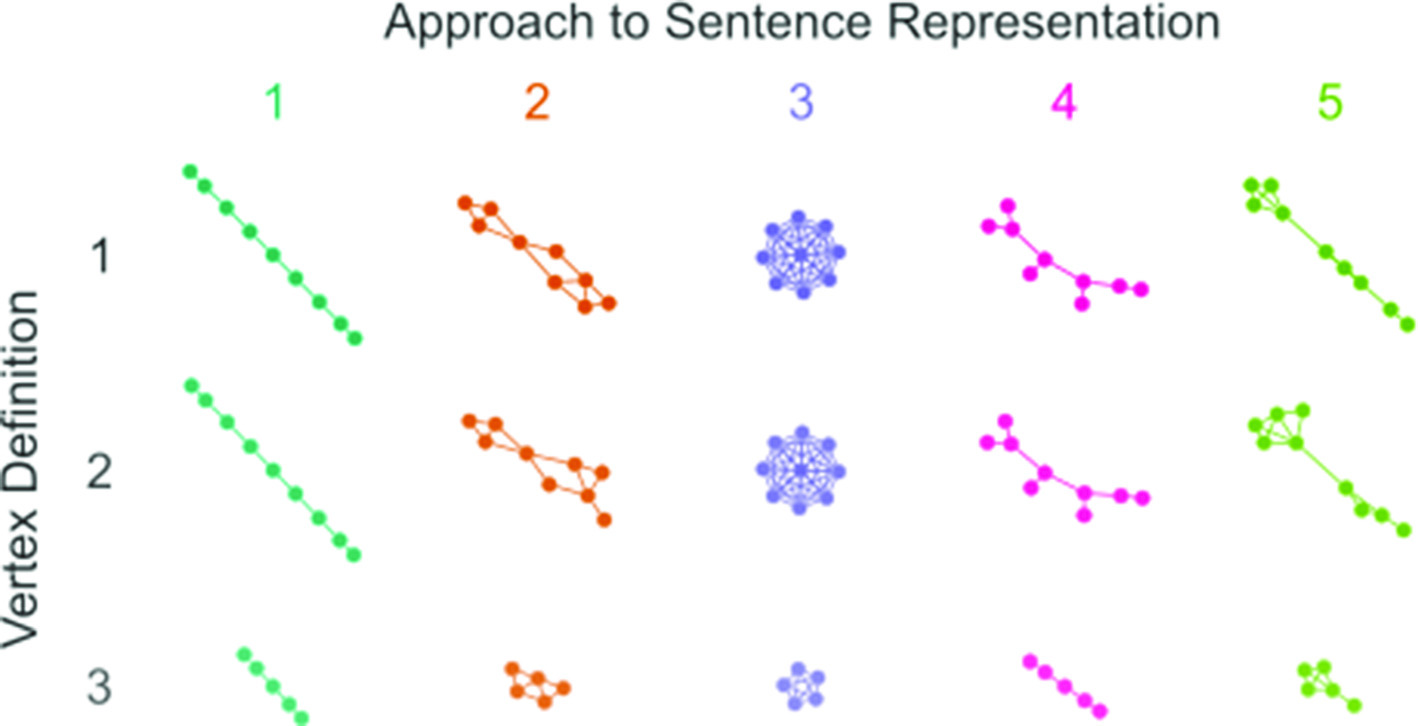
Complex networks offer a powerful framework for modeling linguistic phenomena. This study compares five distinct methods for representing sentences as networks, each with unique edge definitions: (1) a lines approach, where edges represent token (e.g., word) adjacency; (2) a close-range co-occurrence approach, where edges are based on the probability of tokens co-occurring at distance one or two; (3) a cliques approach, where edges connect tokens co-occurring within the same sentence; (4) a dependency-based approach, where edges are defined by syntactic dependencies extracted by a parser; (5) an IF-trimmed-subgraphs approach, where edges are determined by the Incidence-Fidelity (IF) Index. While the first four approaches are well established in the literature, the last one is a novel proposal. We also examined the effects of limiting the vertices to lemmas (i.e., words with inflections removed) and to lexical lemmas (i.e., nouns, adjectives, verbs, and adverbs) as opposed to the unaltered words. Our results reveal that these approaches yield networks with varying average minimal path lengths and degrees, influencing the interpretation of results. While small-world behavior remains consistent across networks, scale-free behavior analysis is affected. Notably, excluding functional words significantly alters degree distributions. We suggest, in order of relevance and according to the resources available, the dependency-based, the close-range co-occurrence, and the lines approaches for cases in which syntactic relations are central, and the IF-trimmed-subgraphs and the cliques approaches for cases in which semantic relations are central.
Davi Alves Oliveira and Hernane Borges de Barros Pereira have contributed equally to this work.
Copyright comment Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
© The Author(s), under exclusive licence to EDP Sciences, SIF and Springer-Verlag GmbH Germany, part of Springer Nature 2024. Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.